CASE STUDY: Store tidsbesparelser med AI workflows

Der er meget få undskyldninger tilbage, for ikke at undersøge hvad AI kan gøre for din arbejdsdag. Jeres viden er i praksis fri, og dagene hvor du skulle have en programmør og/eller en dataingeniør til at processere jeres data for at få de fornødne indsigter ligger bag dig.
Læs og lær hvordan vi brugte Overskrift-data og N8N til, automatisk, at finde en lang række nye danske podcasts, og lad dig inspirere til at bygge dit eget workflow understøttet af kunstig intelligens.
Dine arbejdsprocesser som byggeklodser med N8N
Forud for dette projekt, har vi arbejdet en del med AI via f.eks. programmeringssproget Python. Det performer rigtig godt, men læringskurven og arbejdet med at lære alle de forskellige AI-biblioteker at kende, er stejl. Drag’n’drop-værktøjer kan virke lidt Legoklods-agtige i et professionelt setup. Derudover kommer platformene ofte med begrænsninger, som måske først identificeres sidst i projektet. Efter et par tests af workflow-platformen N8N fandt dette projekt dog hurtigt sin berettigelse.
Byggeklodserne sættes op i platformen N8N, som stiller et kanvas til rådighed hvor du kan bygge et workflow – en klods ad gangen. Platformen N8N giver adgang til mindst 600 forskellige slags klodser, der kan hente data fra en masse forskellige typer kilder (feeds, dine emails, Slack-beskeder etc.), aktivere andre aktiviteter, foretage valg på en masse forskellige logiske baggrunde, kommunikere med AI’er som en selvstændig agent via en prompt du eller den sammensætter og meget andet. Du kan fodre et workflow med data, og det vil typisk blive aktiveret af:
- en indbygget timer (f.eks. samme tidspunkt hver dag)
- en begivenhed (f.eks. en bruger der skriver sig op til et nyhedsbrev eller udfylder en anden online formular)
- en besked der møder specifikke kriterier på en Slack- eller Teams-kanal
- hvis du som bruger trykker på en startknap i workflowet – helt manuelt
Et workflow kan behandle, filtrere og berige dit input, og levere et output som simpel tekst inden i N8N, en besked til en Slack-kanal, et kald til et af virksomhedens andre systemer eller en databaseopdatering.
Når et workflowet afvikles, kan det sagtens være den samme proces, uden afvigelser, der kører hver gang “fra klods til klods”. Bliver det nødvendigt, kan et workflow også selv tage højde for at input f.eks. ikke møder nogle krav du har sat. Lad os sige at vi beder en AI identificere et element i et stykke tekst (her navnet på en podcast serie) – men hvad hvis titlen på en podcast ikke findes i teksten og ikke kan identificeres? Så skal vi have workflowet til at styre udenom alle de efterfølgende trin, som antager at en navngiven podcast er fundet, før det afleverer sit endelige resultat.
Toppen af isbjerget
Det er let at finde podcasts fra top 100 lister. Hvis du Google-søger, finder du (nogenlunde) de samme 100 podcasts uge efter uge. Hvis du til gengæld skal bruge det bredest mulige indblik i den danske podcast-sfære, og véd at der findes en podcast til enhver tænkeligt niche, er der brug for mere.
Vi antager at en podcast altid vil blive omtalt et sted online. Med Overskrifts medieovervågning oprettes en søgning på omtaler af podcasts i forskellige former. Det kunne også have været YouTube videoer eller omtaler af andre typer medier, men lige her arbejder vi altså med podcasts. Hver eneste gang en podcast omtales, bliver det fundet af søgningen, og med den aktuelle søgning sker det op til 100 gange dagligt.
Vi har altså en lind strøm af podcast-omtaler fra danske kilder, og vi ønsker at finde adressen på podcasts vi ikke kender i forvejen, så vores dækning af kilder kan blive så bred som muligt.
For at gøre dette tilgængeligt for N8N bruger vi et resultat-feed fra Overskrift i formatet RSS. N8N forstår hvor titel og brødtekst i omtalerne skal findes når den modtager det i RSS-format. Titel og brødtekst uddrages til det videre workflow.
Forbered data til din sprogmodel, før du bruger tokens
Sprogmodeller er ikke gratis. Du kan chatte ret længe med ChatGPT eller Google Gemini, før de beder om penge, men laver du en app, der prompt’er en AI-model, afregnes der i tokens. Sender din applikation en prompt til en AI, tæller hvert ordstykke og tegnsætning som et token – både fra dit input og det output AI’en producerer. Jo færre ord du sender og beder om at modtage, jo færre tokens koster din prompt og jo mindre bliver din regning fra AI-udbyderen.
Det betyder f.eks., at det er en rigtig god idé at fjerne evt. dubletter fra dit input, før du sender din prompt til AI’en. Det gælder især hvis du, som i dette eksempel, sætter en proces til at køre af sig selv igen og igen på en forholdsvis uforudsigelig mængde input-data. Alternativt kan du ende med en overraskende stor regning.

Ryd og eller “vask” data, før du beder sprogmodellen forholde sig til det. I N8N findes en simpel byggeklods til formålet kaldet Remove duplicates (her har vi navngivet den Filter out old results). Hvis der er dubletter i feedet fra Overskrift fra sidste gang vi kørte workflowet, bliver de fjernet, før vi bruger AI tokens på at behandle dem.
Brug sprogmodellen, men kun til det den er god til
Antag altid at din AI eller sprogmodel er en upålidelig hjælper, der kan finde på at slynge påstande ud, som du ikke i situationen har mulighed for at tjekke. Holder du til gengæld nogle fakta op foran din AI og beder den forholde sig til disse, uden at antage at den har adgang til faktuel viden, så ved den også at du åbenlyst kan afgøre om den taler sandt eller falsk. Sørger du selv for at indskrænke risikoen for forkerte svar, f.eks. ved at give den al den nødvendige information til at ræsonnere sig frem til et korrekt svar, er risikoen for et forkert svar minimal.
Dét benytter vi os af her. Dels ved at fodre den med al den relevante data den skal bruge til sit ræsonnement, men som en bonus kan vi derfor også vælge en mindre og billigere sprogmodel (her Google Gemini 2.5-flash) og vi kunne måske endda vælge at køre vores egen meget lille sprogmodel på egen hardware, så vi er helt fri for eksterne leverandører (og deres regninger).
For hver medieomtale af podcasts, beder vi AI’en om at uddrage titlen på podcast-serien fra den tekst medieovervågningen har fundet til os, og hvis den ikke entydigt kan identificere netop ét navn på podcasten, skal dét være dens output.
En sprogmodel er god til at behandle tekst af en vis størrelse og til at uddrage pointer man beder den om at uddrage. Hvis du antager at den har viden, som den måske/måske ikke har, så antag, at den ikke har den nødvendige viden – og derfor hallucinerer og digter sit eget svar.
Vi uddrager titlen ($json.title) og brødteksten ($json.content) fra podcast-omtalen ind i en prompt:
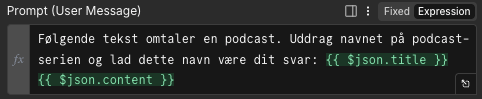
Input til AI Agent-klodsen er altså en liste af podcast-omtaler, output er en liste af titler på podcasts. Vi mangler dog stadig internet-adressen (URL’en) på podcasten.
Spørg Apple
Med lidt ordinær Google-søgning, viser det sig at Apple tilbyder et opslag i deres podcast-database via et åbent såkaldt søge-API. Input til søge-API’et er navnet på en podcast (eller en person eller noget andet der kan være en del af en podcasts beskrivelse) – output er en maskinlæsbar liste af matchende podcasts eller episoder, inklusiv en masse ekstra-information som navnet på udgiveren, seneste udgivelse, billedet der skal vises sammen med podcasten eller episoden, hvilke genrer den dækker og den helllige gral vi har jagtet hele tiden: Adressen på podcastens feed.
En sidste rengøring
Inden adresserne på de nyfundne podcasts gemmes, skal der ryddes lidt op.

Kun de relevante værdier fra Apple’s database skal videreføres, tomme resultater udelades og evt. duplikater skal også fjernes. Men hov – blev duplikaterne ikke fjernet før vi bad AI’en om at uddrage podcast-titlen? Jo, men teoretisk set kan den samme podcast godt blive omtalt i to eller flere uafhængige omtaler, og det er stadig kun interessant at gemme en podcast en enkelt gang i databasen. Derfor køres “Remove Duplicates” en gang til, før de nyfundne podcasts gemmes i databasen.
Beregnet besparelse
Virker det omstændeligt? Så prøv at forestille dig denne proces afviklet manuelt. Medieovervågningen af omtaler af podcasts giver små hundrede resultater på de travleste dage. At gennemlæse hvert resultat, afgøre om en podcast-omtales og i så fald hvad titlen, manuelt finde adressen ved at slå op i f.eks. Apple Podcasts og derefter at afgøre om den er en duplikat eller tidligere er tilmeldt listen af podcast-kilder. Der ligger mindst en times manuelt arbejde pr. dag.
Nu har vi en liste af præ-kvalificerede potentielle kilder, som skal afvises eller tilmeldes. Afvisninger sker f.eks. hvis en ikke-dansk-relateret podcast findes, og de er jo meget nemme at spotte.
Workflow’et startes to gange i døgnet og opdaterer listen af nye podcasts. Vi kan løbe listen af nye podcasts igennem, når der er tid. Fra en times tid til maksimalt 5 minutter på tilmelding af nye podcasts pr. dag, og langt de fleste finder vi før eller i forbindelse med udgivelsen af den første episode.
Flere optimeringer?
Med et forholdsvis simpelt N8N-workflow og en lille smule AI har vi sparet masser af tid (adskillige timer pr. uge).
Vi kunne sætte endnu en klods ind i workflowet, som vha. AI kan afgøre hvilket sprog podcast’en er, så listen af potentielle podcast vi skal forholde os til bliver endnu kortere, men for nuværende vil sådan en optimering ikke stå mål med den minimale indsats øjet gør, når det bevæger sig ned over en liste af potentielt nye podcasts.
Det er en aktiv beslutning, at workflow’et ikke automatisk skal tilmelde nye podcasts til Overskrifts kildeliste. Igen er indsatsen nu så overskuelig, at optimeringen vil være for dyr i forholde til det forventede udbytte, men samtidig kan vi også holde os orienteret om hvilke nye podcasts der udkommer, og det er også med til at give yderligere værdi med minimal indsats.
Brug for hjælp?
Workflow-platforme har eksisteret længe, men understøttet af AI er værdien eksploderet.
Er denne case relevant for dig, og kunne du bruge hjælp eller sparring til AI+Workflow-understøttet analysearbejde, så tag en genvej til erfaringen og kontakt os.